Services like Twitter and Slack have functionality that attempts to
interpret parts of the plain text of tweets or message as entered by
the user. Pieces of the text that look like links, mentions of another
user, hash tags, or stock symbols, cause additional meta data to be
added to the object representing the message, so that receiving clients
can mark up those pieces of text in a special way. Twitter calls this
meta data Tweet
Entities and for each piece of interpreted text, it includes
indices for the start and end of along with additional information
depending on the type of entity. A client can then do in-line
replacements at the exact character indices, e.g. by making it into a
hyperlink. Twitter Entities served as inspiration for XEP-0372:
References.
References can be used in two ways: including a
reference as a sibling to the body element of a
message. The begin and end attributes then point to the indices of
the plain text in the body. This would typically be used if the
interpretation of the message is done by the sending client.
Alternatively, a service (e.g. a MUC service) could parse incoming
messages and send a separate stanza to mark up the original stanza. In
this case you need a mechanism for pointing to that other message.
There have been two proposals for this, with slightly differing
approaches, and in the examples below, I'll use the proto-XEP Message Fastening. While pointing to the stanza ID of
the other message, it embeds a reference element in the
apply-to element.
Mentioning another user
Let's start out with the example of mentioning another user.
The MUC service then parses the plain-text message, and finds a reference to my nickname prefixed with an @-sign, and sends a stanza to the room that marks up the message Kev sent to me.
This stanza declares that it is attached to the previous message by the stanza ID that was included with the original stanza. In its payload, it includes a reference, referring to the characters 13 through 19. It has a mention child pointing to my occupant JID. Alternatively, the room might have linked to my real JID. A client can then alter the presentation of the original message to use the attached mention reference:
The characters referencing @ralphm are now highlighted, hovering the mention shows a tooltip with my full name, and clicking on it brings you to a page describing me. This information was not present in the stanza, but a client can use the XMPP URI as a key to present additional information. E.g. from the user's contact list, by doing a vCard lookup, etc.
Note:
The current specification for References does not have defined child elements, but instead uses a type attribute and URIs. However, Jonas Wielicki Schäfer provided some valuable feedback, suggesting this idea. By using a dedicated element for the target of the reference, each can have their own attributes, making it more explicit. Also, it is a natural extension point, by including a differently namespaced element instead.
Referring to previous messages
<message from="room@muc.this.example/Ge0rG"
type="groupchat">
<stanza-id xmlns="urn:xmpp:sid:0"
id="2019-09-02-3" by="room@muc.this.example"/>
<reference begin="0" end="6" xmlns="urn:example:reference:0">
<mention jid="room@muc.this.example/ralphm"/>
</reference>
<reference begin="26" end="32" xmlns="urn:example:reference:0">
<message id="2019-09-02-1"/>
</reference>
<body>@ralphm did you see Kev's message earlier?</body>
</message>
Unlike before, this example does not point to another stanza with apply-to. Instead, Ge0rG's client added references to go along with the plain-text body: one for the mention of me, and one for a reference to an earlier message.
These two examples show two separate instances of a person
reacting to the previous message by Ge0rG. It uses
the protocol from Message
Reactions, another Proto-XEP. However, I expanded on it by
introducing two new attributes. The label allows for a textual shorthand, that
might be typed by a user. Custom emoji can be represented with the
img attribute, that points to a XEP-0231: Bits of
Binary object.
The attached emoji are rendered below the original message, and hovering over them reveals who were the respondents. Here my own reaction is highlighted by a squircle border.
Including a link
<message from="room@muc.this.example/ralphm" type="groupchat">
<stanza-id id="2019-09-02-7" by="room@muc.this.example"
xmlns="urn:xmpp:sid:0"/>
<body>Have you seen https://ralphm.net/blog/2013/10/10/logitech_t630?</body>
</message>
Here the MUC service marks up the original messages with an explicit link reference. Possibly, the protocol might be extended so that a service can include shortened versions of the URL for display purposes.
Logitech input devices are my favorite. This tiny bluetooth
mouse is a nice portable device for every day use or while
traveling.
The client has used the markup to fetch meta data on the URL and presents a summary card below the original message. Alternatively, the MUC service could have done this using XEP-0385: Stateless Inline Media Sharing (SIMS):
<message from="room@muc.this.example"
type="groupchat">
<stanza-id xmlns="urn:xmpp:sid:0"
id="2019-09-02-8" by="room@muc.this.example"/>
<apply-to xmlns="urn:xmpp:fasten:0"
id="2019-09-02-7">
<reference begin="14" end="61" xmlns="urn:example:reference:0">
<link url="https://ralphm.net/blog/2013/10/10/logitech_t630"/>
<card xmlns="urn:example:card:0">
<title>Logitech Ultrathin Touch Mouse</ulink></title>
<description>Logitech input devices are my favorite. This tiny bluetooth mouse is a nice portable device for every day use or while traveling.</description>
</card>
<media-sharing xmlns='urn:xmpp:sims:1'>
<file xmlns='urn:xmpp:jingle:apps:file-transfer:5'>
<media-type>image/jpeg</media-type>
<name>ultrathin-touch-mouse-t630.jpg</name>
<size>23458</size>
<hash xmlns='urn:xmpp:hashes:2' algo='sha3-256'>5TOeoNI9z6rN5f+cQagnCgxitQE0VUgzCMeQ9JqbhWJT/FzPpDTTFCbbo1jWwOsIoo9u0hQk6CPxH4t/dvTN0Q==</hash>
<thumbnail xmlns='urn:xmpp:thumbs:1'uri='cid:sha1+21ed723481c24efed81f256c8ed11854a8d47eff@bob.xmpp.org' media-type='image/jpeg' width='116' height='128'/>
</file>
<sources>
<reference xmlns='urn:xmpp:reference:0' type='data' uri='https://test.ralphm.net/images/blog/ultrathin-touch-mouse-t630.jpg' />
</sources>
</media-sharing>
</reference>
</apply-to>
</message>
Unlike XEP-0308: Last Message Correction, this example uses Fastening to refer to the original message. I would also lift the restriction on correcting just the last message, but allow any previous message to be edited.
ralphm
Some more thoughtful reply
Upon receiving the correction, the client indicates that the
message has been edited. Hovering over the marker reveals when the
message was changed.
Editing a previous message that had fastened references
Upon receiving the correction, the client discards all fastened
references. The body text was changed, so the reference indices are
stale. The room can then send a new stanza marking up the new
text:
Fastening should also gain a way to unfasten
explicitly. I think that should use the
stanza ID of the stanza that included the earlier fastening. This
allows for undoing individual emoji reactions.
Unfastening should probably not use the proto-XEP on Message
Retraction. That is for retracting the entire original
message plus all its fastened items, and invalidating all message
references pointing to it.
It might make sense to have a separate document
describing how to handle stanza IDs, so that all specifications
could point to it instead of each having their own algorithm. In
different contexts, different IDs might be used. The other
proposal for attachments, XEP-0367:
Message Attaching, has a section (4.1) on this
that might be taken as a start.
In the discussion leading up to this post, a large
part was about how to handle all these things attached/fastened
to messages in message archives. This is not trivial, as you
likely don't want to store a sequence of stanzas, but of
(original) messages. Each of those message then might have one or
more things fastened to it, and upon retrieval, you want these to
come along when retrieving a message. Some of these might be
collated, like edits. Some might cause summary counts (emoji,
simple polls) with the message itself, and require an explicit
retrieval of all the reactions, e.g. when hovering the reaction
counts.
Details on message archive handling is food for a later post.
I do think that having a single way of attaching/fastening things
to messages makes it much easier to come up with a good solution
for archive handling.
I didn't provide examples for stanza
encryption, but discussions on this suggested that
stanzas with fastened items would have an empty
apply-to, including the id attribute, so that message archives
can do rudimentary grouping of fastened items with the original
message.
I didn't include examples on Chat Markers, as its
current semantics are that a marker sent by a recipient applies
to a message and all prior messages. This
means the marker isn't really tied to a single message. I think
this doesn't match the model for Message
Fastening.
Posted at 13:29, updated 2019-09-09 16:37 by ralphm #. Keywords: XMPP, rich messaging, reactions, Twitter and Slack.
For me, Christmas and Jabber/XMPP go together. I started being
involved with the Jabber community around the end of 2000. One of the
first things that I built was a bot that recorded the availability
presence of my online friends, and show this on a Christmas tree.
Every light in the tree represents one contact, and if the user is
offline, the light is darkened.As we are nearing Christmas, I put the
tree up on the frontpage again, as many years
before.
Over the years, the tooltips gained insight in User Moods and
Tunes, first over regular Publish-Subscribe, later enhanced with the
Personal Eventing Protocol. A few years later, Jingle
was born, and in 2009, stpeter wrote a great
specification that solidifies the relationship between
Christmas and Jabber/XMPP.
Many things have changed in those 16 years. I've changed jobs
quite a few times, most recently switching from the Mailgun team at
Rackspace, to an exciting new job at VimpelCom as Chat
Expert last April, working on Veon
(more on that later). The instant messaging landscape has changed
quite a bit, too. While we, unfortunately, still have a lot of
different incompatible systems, a lot of progress has been made as
well.
XMPP's story is long from over, and as such I am happy and honored
to serve as Chair of the XMPP Standards Foundation since last month.
As every year, my current focus is making another success of the
XMPP Summit
and our presence with the Realtime Lounge and Devroom at FOSDEM in
Brussels in February. This is always the highlight of the year, with
many XMPP enthousiasts, as well as our friends of the wider Realtime
Communications, showing and discussing everything they are working
on, ranging from protocol discussions to WebRTC and IoT
applications.
Like last year, one of the topics that really excite me is the
specification known as Mediated Information
eXchange (MIX). MIX takes the good parts of the Multi User
Chat (MUC) protocol, that has been the basis of group chat in XMPP for
quite a while, redesigned on top of XMPP Publish-Subscribe. Modern
commercial messaging systems, for business use (e.g. Slack and
HipChat), as well as for general use (e.g. WhatsApp, WeChat, Google's
offerings), have tried various approaches on the ancient model of
multi-part text exchange, adding multi-media and other information
sources, e.g. using integrations, bots, and
cards.
MIX is the community's attempt to provide a building block that
goes beyond the tradional approach of a single stream of
information (presence and messages) to a collection of
orthogonal information streams in the same context.
A room participant can select (manually or automatically by the user
agent) which information streams are of interest at that time. E.g.
for mobile use or with many participants, exchanging the presence
information of all participants can be unneeded or even expensive (in
terms of bandwidth or battery use). In MIX, presence is available as a
separate stream of information that can be disabled.
Another example is Slack's integrations. You can add streams of
information (Tweets, continuous integration build results, or pull
requests) to any channel. However, all participants have no choice to
receive the resulting messages, intermixed with discussion. The
client's notification system doesn't make any distinction between the
two, so you either suffer getting alerts for every build, or mute the
channel and possibly miss interesting discussion. The way around it is
to have separate channels for notifications and discussion, possibly
muting the former.
Using MIX, however, a client can be smarter about this. It can
offer the user different ways to consume these information streams.
E.g. notifications on your builds could be in a side bar. Tweets can
be disabled, or modeled as a ticker. And it can be different depending
on which of the (concurrent) clients you are connected with. E.g. the
desktop or browser-based client has more screen real-estate to show
such orthogonal information streams at the same time, a mobile client
might still show the discussion and notifications interleaved.
All-in-all MIX allows for much richer, multi-modal, and more
scalable interactions. Some of the other improvements over MUC include
persistent participation in channels (much like IRC bouncers, but
integrated), better defined multi-device use (including individual
addressing), reconnection, and message archiving. I expect the
discussions at the XMPP Summit to tie the loose ends as a prelude to
initial implementations.
I am sure that FOSDEM and the XMPP Summit will have many more
exciting topics, so I hope to see you there. Until then, Jabber
on!
Posted at 14:28 by ralphm #. Keywords: xmpp, jabber, christmas, mailgun, rackspace, vimpelcom, pubsub and mix.
Logitech is my brand of choice for input devices. Unfortunately,
though, Logitech seems to focus on their unifying receiver for most of
their stuff, to the detriment of their Bluetooth offering. Every now
and then, they do come out with a nice Bluetooth device, usually
targetting ultrabooks or tablets. Last month I stumbled upon the new
Logitech
Ultrathin Touch Mouse (t630). As usual, it is marketed for
Windows compatibility, with Linux officially not supported. They do
have a second model targetted to Mac users with the t631,
but I suspect the only difference is its color.
Fortunately, this device mostly works fine on my Ubuntu 13.04
laptops. Plural, because this tiny mouse can be set up to pair with two
devices, switchable with a switch on the bottom. The only problem is
that, out-of-the-box, gnome-bluetooth cannot
reconnect with the device when it has been powered down or switched
back from the other channel. It turns out that Logitech might not be
following standards, and requires repairing every time. In my search
for similar cases, I found a bug report for another device that has had
similar issues, and the solution presented there also works for the
Ultrathin Touch Mouse.
The trick is to tell gnome-bluetooth to always
send the pincode (0000, as usual) upon
connecting. For this, it needs an entry in /usr/share/gnome-bluetooth/pin-code-database.xml like this:
I filed a bug report
to have this included by default. After adding the entry, add the mouse as a new input device and it should work as expected.
On to the mouse' features. Besides detecting motion with its bottom
laser, the surface is a touch pad that can be depressed as a whole.
Pressing in the top left and top right corner will trigger the left and
right mouse button events (button 1 and 3). To do a middle-click, you
have to press in the center of the touch pad, not at the top middle, as
you'd expect. Vertical and horizontal scrolling can be done with swipe
gestures, respectively up/down and left/right. This will trigger
buttons 4 through 7.
On top of that, there are some additional gestures, which Logitech
has pictured in a handy
overview. First, there is a two-finger left or right swipe
for doing previous and next actions. In X11 this will trigger buttons
8 and 9, and Firefox, for example, will respond to move back and forth
in a tab's history. The other three gestures generate keyboard events,
instead of the usual mouse events. A double-finger double-tap yields a
press and release of the Super_L key. In Unity this
brings up the dash home by default. Finally there are swipes from the
left edge and from the right edge. The former triggers Ctrl_L
Super_L Tab, which switches between the two last used tabs
in Firefox, the latter Alt_L Super_L
XF86TouchpadOff, which doesn't have a default action bound
to it, as far as I can tell. Logitech also mentions the single-finger
double tap, but that doesn't seem to register any event in the input
handler.
The mouse can be charged with via its micro-USB connector, also on
the bottom, with a convenient short USB cable in the box. The micro-USB
connector on that cable is also angled so the mouse doesn't have to be
upright when charging. The battery state is reported to the kernel, but
there is another bug in upower that will make
batteries in bluetooth input devices show up as laptop
batteries.
Having used the mouse for a few days now, I like it a lot. It is
really tiny, but not in a bad way (for me). The two-finger swipe
gestures are a bit tricky to get right, but I don't really use them
anyway. I also tried hooking it up to my Nexus 7, and that works
nicely. All-in-all a great little device, especially while
travelling.
Posted at 14:00 by ralphm #. Keywords: logitech, bluetooth and mouse.
Kicking off the revival of this publication, I recently did a guest
post on our use of Elasticsearch at Mailgun. Since I have joined
the Mailgun team at Rackspace in May, my primary project was to
reimplement the Mailgun customer logs so that we can serve
billions of searchable events. Head over to the HackerNews
page for some additional details.
Posted at 13:47 by ralphm #. Keywords: mailgun, rackspace, elasticsearch, logstash and kibana.
Atom and RSS feeds are typically used to support syndication of
existing works, most commonly weblog entries. They are XML documents
that provide a common representation that can be consumed by feed
readers, unlike the HTML pages for such a work. ActivityStreams is a
format for syndicating social activities around the web.
Based on the Atom Syndication Format, it tries to provide a feed for
activities, rather than existing works. This includes the
act of posting a blog entry, but can also express
activities typical for social networking sites, like adding friends,
liking something or affirming an RSVP for an
event.
At Mediamatic Lab,
we've recently gave notifications an overhaul. We had some code
scattered around for sending notices to users, like when they received
a friend request. We wanted to add a bunch of notifications so that
people are aware of what happens in the network of sites, with their
profile or works they've created. For example, when someone tags a
person as being in a picture, it would be nice for that person to get a
message about that. We also have a collection of RFID-enabled
Interactive Installations that generate XMPP notifications for our
backchannel system. I'll come back on this.
Whenever something happens that you want to send a notification
for, there are a couple of things that you want to include in the
notification: what happened, when it happened, and which persons and/or
things are involved. The concepts of ActivityStreams turned out to
coincide with how we wanted the notification to work. It abstracts
activities in actors, objects and targets, along with a human-readable
text to describe each activity.
A verb is an identifier for the kind of activity that has taken
place. A verb takes the form of a URI, much like rel
attributes in Atom link elements, or properties in RDF. The most basic
verb is post, with the URI
http://activitystrea.ms/schema/1.0/post.
An actor is the (usually) person that has performed the activity.
Objects are the main persons or things that the activity was performed
upon. For example, when I post a picture, I am the actor, and the
picture is the object. A target is an object an action was done to. An
example could be the photo album my uploaded picture was posted to.
Actors, objects and targets usually have a URI, a title and an object
type, similar to RDF classes.
Our new notification system does a couple of things whenever a an
activity has taken place. It figures out the verb, actor, object and
possibly the target and then creates a notification entry. It then
calculates the parties that should get this notification in their
inbox. This is usually the actor and the owner of the object. A
person's profile is always owned by itself, so when the object is a
person, that person would get a notification on things happening to
them. When a party is not local (i.e. on another site in the
federation), the notification is sent to the other site to be processed
there. Each person's inbox is viewable as a stream of activities, much
like Jaiku or Facebook, and is also published as an ActivityStreams
feed (e.g. ralphm's
activities. New notifications can then be processed by other
modules.
One of them is the Message module, that sends out e-mails for
notifications, according to personal preferences. For now, you can
choose what kind of notifications you want to receive an e-mail about,
by choosing the verbs you are interested in. Examples currently
include: friend requests/confirmations, changes to things you own,
people liking, linking to, RSVPing (for events), sharing (to Twitter,
Facebook, etc) or commenting on things you own, and people tagging you
in a picture.
Another module is the Publish-Subscribe module, that provides
XMPP
Publish-Subscribe nodes for each person, along with a node
for all notifications for that site. This allows for applications that
use the stream of activities for a person or the whole site, in
near-real-time. An example could be a mobile app to track activity for
you and/or your friends, or IM notifications much like Identi.ca or
Jaiku.
Another possibility is a backchannel. We
developed a backchannel system for events we deploy our RFID-enabled Interactive
Installations at. A backchannel feed is aggregated from a
configurable set of sources, of which the incoming items are formatted
into notifications to be put up on a live stream. Every time someone
takes a (group) picture with our ikCam, the image is
posted on the backchannel, along with a text listing the people in the
picture.
On top of that, we also can include tweets by tracking particular
keywords and people. We use (and improved) twitty-twister
to interact with Twitter's Streaming API from Twisted. I've recently
changed the streaming code of twisty-twitter to consume JSON instead of
the deprecated XML (with a bunch of tests), and a way to detect
unresponsive connections.
With activities now also available as XMPP notifications, the
logical step was to consume these for the backchannel as well. We have
an office
backchannel on a big screen that tracks Twitter for keywords
related to Mediamatic and its events, and the notifications from our
interactive installations. It now also includes activity on our sites,
and this turns out to be a great way to see everything happening in our
sites.
So, did it all go smoothly? No. We found quite some things in the
ActivityStreams' concepts in combination with anyMeta and our
interactive installations that we didn't expect when we started the
project.
One of the big ones was Agents. Our interactive installations have
their own user accounts to take pictures, process votes, etc. These
accounts have special privileges to perform actions like making all
people in an ikCam picture contacts in the network. We also have a
Physical I-like-it button, which is an RFID reader placed next to a
physical object (e.g. a painting) that has a representation in one of
the sites. When reading a tag, it creates a like
relationship between the holder of the RFID tag and the object. When we
just enabled the first enabled the new notifications functionality, a
message popped up on the backchannel: ikPoll Agent likes
iTea.
That was quite unexpected but quite logical when we thought about
it. ikPoll Agent is the user account for the I-like-it button, that is
powered by the same software as our more generic ikPoll installations.
We defaulted the actor of an activity to the user account performing
the action. Although the agent creates a link from the person to the
object, the link was not created on behalf of the physical user. So we
needed to introduce the concept of Agents, and have that also stored
and communicated along with activities. The same action would now yield
an entry with the title 'ralphm likes iTea (via ikPoll Agent).
Another was pictures taken with the ikCam. Besides posting the
image, all actors are tagged in the picture, the picture is optionally
linked to an event and a location. This yields a bunch of
notifications, where we would like to have only one: ralphm took
a self-portrait. We have started work on compound activities
that would have the enclosed activities linked to it and back, a bit
like the Atom
Threading Extension.. This would allow aggregators like the
backchannel only show the umbrella notification.
A final one was our verb link. This was supposed
to be a catch-all verb for the activity of creating a semantic link
between two things, of which the predicate didn't already have its own
verb (like friending, liking, etc.). It now looks like having a
notification like 'person A linked to thing B' might need some more
information. An e-mail notification at least has the links to
respective pages, but that doesn't quite work on a backchannel beamed
on a big screen. For now we ignore such notifications for the
backchannel, until we have a better solution. It might be that we need
to include the link's predicate in the notification, or make links
themselves first-class citizens (with their own URI).
Going to FOSDEM and/or the 10th
XMPP Summit in Brussels? I'll be talking about this and other
topics in my talk on Federating Social Networks on Saturday 5
February.
Posted at 20:50, updated 2011-02-03 10:32 by ralphm #. Keywords: activitystreams, xmpp, pubsub, federation, atom, rfid and fosdem.
Last week, Blaine Cook
congratulated me on Idavoll
being in Apple Mac OS 10.6 Server, as its Notification Server. I did
have contact with Apple's server team ages ago, about them using
Idavoll and having added some customizatons, but never knew where it
ended up. The list of Open
Source projects used in Apple's products confirms the use of
Idavoll, and Wokkel, too, as
a dependency of Idavoll. Cool!
Idavoll, and thus Notification Server, is a generic XMPP
publish-subscribe service, in Python with Twisted. Upon inspection of
the code and the differences against the mentioned versions, most of
the customizations match those I was already aware of: an SQLite
backend, the whitelist node
access model and associated member affiliations. The link to
Notification Server at the open source list goes nowhere (yet), so I am
unsure about the actual license of their additions. I contacted the
server team, and will write again if I have more news on this.
At the nice post by Jack Moffitt on Apple's use
of XMPP, Kael mentions the presence of more
Publish-Subscribe
goodness in Calendar Server. This is actually the stuff that
uses Notification Server for push
notification in iCal. As Jack says, it is truly great to see
large corporations like Apple to embrace XMPP like this. I really wish
Google Calendar had a similar feature. Now I only get meeting invites
through e-mail. Apple's particular use of Publish-Subscribe reminds me of
Joe Hildebrand's effort on WebDAV
notifications, and I think that there are a lot of
applications that could benefit from such push features.
As I touched
upon earlier, at Mediamatic Lab, we use XMPP
Publish-Subscribe for exchanging things for
federation. But we've also built a bunch of interactive installations,
most of them dealing with RFID tags we call ikTags. To name two
examples, the ikCam takes a (group)
picture, uploads it and friends the depicted persons by reading their
tags. The ikPoll
is a polling station where people can 'vote' on questions with the
tag. Typically, there are also publish-subscribe notifications coming
out of those interactions, so you can create a live
stream of things happening at an event like PICNIC. Combined
with the Twitter
Streaming API and our own status messages, this creates an
entertaining back channel, coincidently powered by Idavoll.
Posted at 16:23 by ralphm #. Keywords: idavoll, apple, xmpp, pubsub and iktag.
Two exciting projects I've been recently working on at Mediamatic Lab are two highly
connected sites around the Jewish Community in the Netherlands during
World War Ⅱ. The first is one of the oldest sites we have made, the
Digital Monument.
This site contains verified information on all of the Dutch jews that
have died during WWⅡ along with their households, documented posessions
and known documents and pictures. It is maintained by a team of editors
of the Jewish Historical
Museum.
The second is a brand new community site, to
complement the Monument by allowing anyone to add new information,
pictures and stories on people at the Monument.
The Monument is very impressive, as I learned back at the first
BarCamp
Amsterdam, hosted by Mediamatic. You will know what I mean if
you spend a little as five minutes paging through the site. Today,
however, I want to talk about the technology behind both sites.
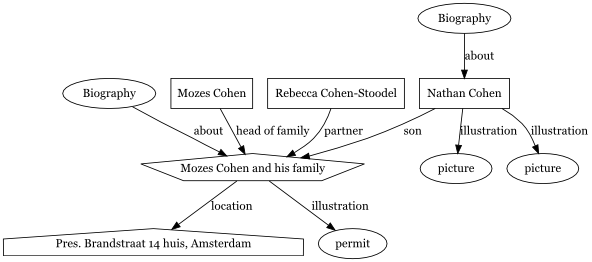
Data Model Changes
The data in the Monument is highly semantic in nature. People are
part of households, as head-of-family, spouse, son or daughter. Or
some other relation. Households have a location and lists of
possessions. Tied to all of these are supporting documents and
pictures. In anyMeta,
all of these are modeled as things with
edges between them with a certain predicate. A
typical household would be modelled like this:
For the community site, however, we wanted to have more direct
relationships between people: parent-child relations, sibling
relations, partner relations and a more generic (extended) family
relationship. As the community also has most things of the monument
imported, this meant a change in the data model and a subsequent
conversion in the monument.
In anyMeta, (almost) everything is a thing. As such, the
predicate on an edge between two things is also represented by a
thing. This has traditionally been named role.
Like all things in an anyMeta site have a resource
URI, the resource URI of a role is the predicate's URI.
We try to use existing (RDF) vocabularies as much as possible for
this.
For relationships between people, we've used the
knowsOf and friendOf properties
from RELATIONSHIP,
used in FOAF. So this was the first place to look for the desired new
predicates. However, this vocabulary does not have a property for
expressing a generic extended family relationship. Fortunately,
XFN has the
kin relationship type, along with
child, parent,
spouse and sibling.
Richard Cyganiak described how to express XFN relations in
RDF, so we used that to base our predicates on.
Like RELATIONSHIP, most of the XFN properties are subproperties
of the foaf:knows property, and have some
hierarchy themselves, too. In anyMeta, we didn't have the concept of
subproperties, yet, so we added a new role for expressing subproperty
relationships between roles, and introduced the concept of
implicit edges. These are edges with a
superpredicate of the explicit edge that is being created. For
example, the xfn:child property is a subproperty
of foaf:knows. Whenever an edge between two people
gets created with the child role, another implicit one with the knows
role is added, too.
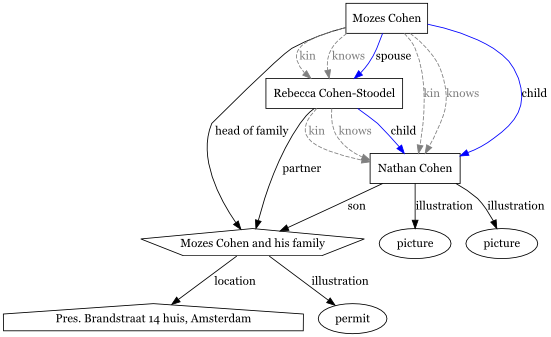
After conversion and with the implicit edges present, the new
data model of the example above looks like this:
The blue arrows are the new, derived edges. A spouse edge is made
between those people that respectively have a head-of-family and
partner relation to the same household (this can be assumed to be
correct for this dataset). For person that have a son or daugther
edge to a household, a child edge is made from the head-of-family and
partner persons (if any) in that household to this person. We haven't
(yet) added derived sibling edges, as this relation depends on the
parents of both persons, too.
You can also see gray, dashed edges. These are the implicit edges
that follow from the property hierarchy. Another thing to notice, is
that the biographies are gone. We put the texts in there directly on
the persons and households, instead.
Besides the regular pages of all people, households and other
things, you can also use our semantic browser to look at the
relationships between things. For example, Mozes and his
family can be browsed from here.
Posted at 14:46 by ralphm #. Keywords: mediamatic, anymeta, jewish monument, semantic web, relationships and xfn.
Even before I got to work for Mediamatic Lab, Mediamatic
was using Twisted.
My friend Andy Smith used it
for a bunch of projects around physical objects, usually involving some
kind of RF tags. Examples include the Symbolic Table and
the Friend Drinking
Station. From this grew fizzjik, a Twisted based
library that implements support for several kinds of RFID readers,
network monitoring and access to online services like Flickr and of
course anyMeta.
On the other hand, I have dabbled in Twisted for quite a while now,
mostly contributing XMPP support in Twisted Words and through the
playground that is known as Wokkel. But why go through all
that effort, while there are a several different Python-based XMPP
implementations out there? And why does Mediamatic use Twisted? Why do
I believe Twisted is awesome?
First of all, we like Python. It is a great little language with
extensive library support (batteries included), where
everything is an object. Much like in anyMeta. It is a language for
learning to program, to code small utility scripts, but also for entire
applications.
But going beyond that, building applications that interact with
different network protocols and many connections all at the same time
is a different story. Many approach such a challenge by using preemtive
threading. Threads are hard. Really hard. And Python has the GIL,
allowing the interpreter to only execute byte codes in one thread at a
time.
So in comes Twisted. Twisted is a framework for building networked
applications in Python, through a concept known as cooperative
multitasking. It uses an event loop that hands off processing of events
(like incoming data on a socket or a timer going off) to non-blocking
functions. Events loops are mostly known from GUI toolkits like GTK,
and so Twisted goes even beyond networking by working with such
toolkits' event loops, too. As most network protocol implementations
only have a synchronous interface (i.e. one that blocks), Twisted
includes asynchronous implementations of a long list of network
protocols. For the blocking interfaces that come from C libraries, like
databases, Twisted provides a way to work with
their threads, while keeping all your controlling
code in the main thread. Asynchronous programming does take some
getting used to, hence Twisted's name.
So how do we use Twisted? Well, a recent application is our recent
RFID polling system. It allows people to use their ikTag (or any card
or other object with a Mifare tag), tied to their user account on an
anyMeta site, to take part in a poll by having their tag read at an
RFID reader corresponding to a possible answer. The implementation
involves:
Communication with one or more RFID readers (that
also have output capabilities for hooking up lamps, for
example).
Communication over HTTP to access anyMeta's API to
store and process votes.
Network availability monitoring (can we access the
network and specifically our anyMeta site?)
Power management monitoring (do we still have
power?)
Device monitoring. Are RFID readers plugged in
or not? Which device handle are they tied to? Also watch coming
or leaving devices.
A (GTK-based) diagnostic GUI
Additionally, we also want to show polling results, so we have a
browser talking to a local HTTP server and a listener for XMPP
publish-subscribe notifications.
This is quite a list of tasks for something as seemingly simple as
a polling stations. But wait: there can be multiple readers tied to a
particular poll answer, likely physically apart, a polling question can
have maybe 50 answers (depending on the type of poll, like choosing
from a collection of keywords) or there could be a lot of questions at
one event.
So, back to Twisted. Twisted has HTTP and XMPP protocol support
(both client and server-side), can talk to serial devices (like your
Arduino board) and DBus (for watching NetworkManager and device events)
and provides event loop integration with GTK to also process GUI events
and manipulate widgets based on events. Together with Wokkel, it powers
the exchange of information in our (and your?) federating social
networking sites. In Python. No threads and associated locking. In
rediculously small amounts of code. That's why.
Not yet convinced? Add a Manhole
to your application server, SSH into it, and get an interactive, syntax
highlighted Python prompt with live objects from your application. Yes,
really.
Posted at 16:45 by ralphm #. Keywords: mediamatic, twisted, anymeta, fizzjik, rfid, xmpp, gtk and dbus.
I am attending XMPP Summit #7 and
part of OSCON 2009, with which it is co-located due the kind folks at
O'Reilly. Much like last
year, only this time in San José, California. Unlike the
European version of the summit last February, we hope to focus more on
doing than talking, although there will be plenty of that, of
course.
Suggestions were made to do some interoperability testing, along
with general hacking sessions. I am bringing my implementation of
server-to-server
dialback, and a bunch of other protocol implementations in
Wokkel to the table. While
there are a bunch of other protocol implementations in Python, I think
the Twisted approach is so different that I want people to know about
the ideas behind it. By introducting them to Twisted through Wokkel
should give them at least a glimpse of why I believe
Twisted is awesome.
So, nearing the summit I prepared a bunch of examples around the
XMPP Ping
protocol, as I mentioned before.
Additionally I prepared an example echo
bot on steroids, which is basically a stand-alone XMPP server
that connects to other servers using the server-to-server protocol. It
will accept presence subscriptions to any potential
account at the configured domain, sending presence
and echoing all incoming messages.
Besides the hacking sessions, I planning to discuss
publish-subscribe delete-with-redirect, node collections,
publish-subscribe in multi-user chats and service discovery meta data.
Oh, and we might go on a field trip to discuss Google Wave XMPP-based
federation protocols. Then, after the summit, I will hanging out at
OSCON until Thursday, for hallway meet-ups on federating social
networks with protocols like OpenID, OAuth and technologies like
webfinger and pubsubhubbub. I also brought an RFID reader to play
with.
Posted at 08:53 by ralphm #. Keywords: xmpp, jabber, xs7, oscon2009, server-to-server, publish-subscribe, pubsub and wokkel.
Today's Wokkel
0.6.2 release is to show case some of the features in the
previous 0.6.0 release. Most of the work was part of the things we have
been building at Mediamatic
Lab as part of a restructuring of how we federate our social
networking sites using publish-subscribe.
First of all, I added a preliminary, but functional, implementation
of server-to-server support, using the dialback protocol. This
complements the router code that went into 0.5.0 and Twisted Words
8.2.0 to make a fully stand-alone XMPP server. Note that it does not
implement any client-to-server functionality yet, but this can be added
as separate server-side components now.
To show this off, I have created a bunch of examples around the
XMPP Ping
protocol, for which the protocol implementation itself is also a nice
example of how to write XMPP protocol implementations using Twisted
Words and Wokkel. Be sure to check out these examples.
The other feature I want to mention is publish-subscribe Resources.
They provide an abstraction of (part of) a publish-subscribe service.
The protocol parts are handled by Wokkel. This should make it easier to
do node-as-code scenarios, by just filling in the blanks of the various
methods that are called upon receiving requests from pubsub
clients. I'll create some examples for this shortly.
Posted at 22:18 by ralphm #. Keywords: wokkel, server-to-server, ping, publish-subscribe and pubsub.